Some models guess well. Others guess poorly. But what if you could bring many of them together and get something consistently better? That’s where AdaBoost comes in. Short for Adaptive Boosting, this technique builds a powerful model by combining multiple weak ones—each just slightly better than random guessing.
It doesn't try to be perfect from the start. Instead, it improves step by step, correcting its errors along the way. This guide breaks down how the AdaBoost algorithm works, why it's useful, and when to use it—all without getting buried in technical fluff.
What Is AdaBoost and Why Does It Work?
AdaBoost belongs to a family of machine learning techniques called ensemble methods. Instead of building one complex model, ensemble methods combine several simpler models—called weak learners. These weak learners usually aren’t great by themselves. In AdaBoost, decision stumps are the most common weak learners. A decision stump is a single-split decision tree that offers just enough predictive power to be useful.
The algorithm assigns equal weight to all data points at first. After the first learner is trained, AdaBoost checks which data points were misclassified. It then increases the weight of those points, making them more “visible” to the next learner. Each new learner is trained with this updated view of the data, gradually making the system more accurate.
The strength of AdaBoost lies in its ability to adapt. With every new learner, the algorithm shifts focus toward harder-to-classify examples. At the end of training, each weak learner gets a weight based on how accurate it was, and the final prediction is made using a weighted vote from all learners. This way, even simple models can come together to build a stronger, more capable classifier.
How the AdaBoost Algorithm Works in Practice?
The process begins by initializing equal weights for all training samples. These weights control the influence each sample has on the model's training. After training the first weak learner, the algorithm calculates its error rate. If this error is above 50%, it's discarded. If it's below that, the learner is assigned a weight based on their performance. Better accuracy means more influence.
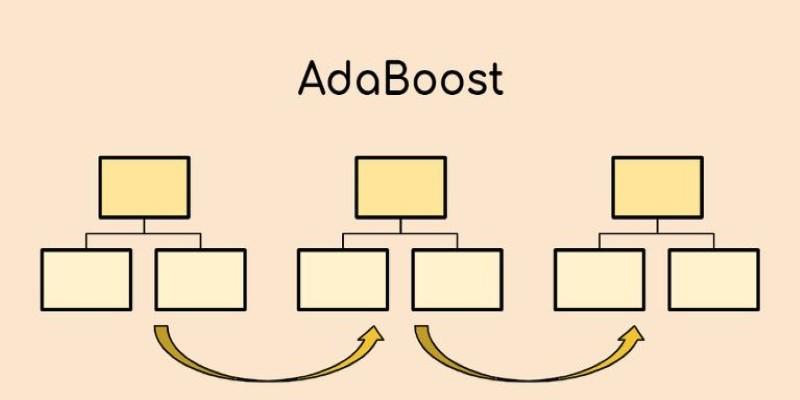
Next, AdaBoost updates the sample weights. Incorrectly classified examples are given more weight so that the next learner focuses on them. This loop continues for a fixed number of rounds or until performance stops improving. Each new learner builds on the foundation laid by the previous ones.
In binary classification, each weak learner casts a vote, weighted by its performance. The class that receives the most combined weight is the final output. For multi-class problems, the general approach is similar, though the math becomes more involved. Still, the focus stays the same: fix the last round’s errors.
This process creates a feedback loop that targets the weak spots in the model’s learning. The more difficult or inconsistent the sample, the more attention it receives in the next round. Over time, this structure creates a model that’s more accurate than any individual learner.
Applications and Benefits of Using AdaBoost
AdaBoost is used in a wide range of machine learning tasks. In image recognition, it has helped power face detection systems. In spam detection, it helps distinguish between legitimate messages and unwanted ones. It has even found uses in medical diagnosis, credit scoring, and other classification problems where accuracy is key.
One major benefit is its simplicity. AdaBoost doesn’t need complex tuning to start working. When paired with decision stumps, the algorithm is easy to implement and runs quickly on smaller datasets. It also tends to avoid overfitting more than some other methods, especially when the number of weak learners is kept reasonable.
The model’s flexibility is another strength. It doesn’t rely on assumptions about the underlying data. This allows it to work with both continuous and categorical variables, and it performs well across a range of domains. Because it improves performance by focusing on errors, it often outperforms single classifiers, especially when the base learners are weak but consistent.
While newer boosting algorithms have improved on AdaBoost’s design, the original version still holds value. It provides a solid introduction to the concept of boosting and remains a benchmark for comparing newer models.
Common Pitfalls and When to Use AdaBoost
Despite its strengths, AdaBoost isn’t a cure-all. One of the biggest issues is its sensitivity to outliers and noise in the data. Because the algorithm increases focus on misclassified points, it may end up overemphasizing incorrect or misleading examples. This can hurt the model’s performance if the data isn’t clean.

AdaBoost can also be slow with large datasets. Each round depends on the results of the last, which means the process isn’t easily parallelized. While it’s fine for smaller tasks, it may not be the best choice for massive datasets.
Interpretability is another trade-off. Although each decision stump is easy to understand, the final model becomes harder to explain as more learners are added. This can be a limitation in fields where transparency is necessary.
Still, when used correctly, AdaBoost is highly effective. It’s best suited for clean datasets where classification accuracy matters more than model simplicity or speed. It works especially well in binary classification problems and serves as a solid baseline before moving on to more complex ensemble methods.
Conclusion
AdaBoost builds its strength from modest parts. Instead of searching for one perfect model, it improves bit by bit—adjusting to its mistakes and focusing harder each time. The algorithm combines weak learners into a model that’s both practical and reliable for many real-world tasks. It doesn’t require deep customization or heavy computing resources to be effective. While it has its limitations, AdaBoost remains a clear example of how machine learning can improve through iteration. For tasks where accuracy counts and the data is clean, AdaBoost still holds its place in the toolbox.