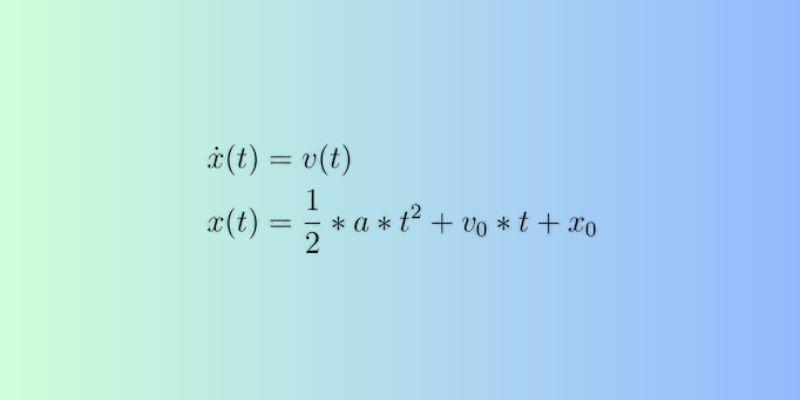GRUs are a significant development in Recurrent Neural Networks that aim to overcome the difficulties of retaining long-term data in an orderly sequence. GRUs provide scalable memory storage and reasoning capabilities, with gating that reduces computational complexity, and are critical for tasks such as language modeling, time-series prediction, and speech recognition.
The Shortcomings of Traditional RNNs
The purpose of traditional RNNs was to represent sequential relations; therefore, they are best suited to problems that require context or order. An input is fed into each cell of an RNN, which then processes it and passes information to the next cell via a hidden state. In theory, the network can remember past data. Nonetheless, RNNs are poor at long-term dependencies.
The gradient values used in training decrease exponentially as the network becomes more complex or the sequence length increases. This issue, also known as the vanishing gradient phenomenon, prevents effective updates to previous layers of the model. Consequently, the network erases key information from the far past and is biased toward including more recent information.
This problem not only reduces the performance of RNNs with long sequences but also leads to unstable, inefficient training. Scholars noticed that to realize their potential, RNNs required a way to manage the flow of information more intelligently —giving the model the ability to remember or forget selectively.
The Emergence of Gated Recurrent Units
Researchers Kyunghyun Cho and others presented the Gated Recurrent Unit (GRU) as a simpler variant of the Long Short-Term Memory (LSTM) network in 2014. LSTMs have addressed the vanishing gradient problem by introducing more gates and a distinct memory cell, but they are also computationally intensive. GRUs offered a more competitive structure—the fundamental concept of gating mechanisms was preserved, without extraneous complexity.
GRUs strike a fine balance of simplicity, speed, and accuracy. They filter the information entry using two main gates:
Update Gate:
The update gate serves a significant purpose in determining to what degree the past concealed condition will affect the present one. It also acts as a filter: as its value approaches 1, it retains previous knowledge; when it approaches 0, the model can focus on new inputs. This balance will ensure the model does not rewrite crucial long-term information too rapidly.
Reset Gate:
The reset gate determines how much of the past should be forgotten. When this gate has a low output, it effectively acts as a reset button for the GRU's memory, giving more weight to the current input. This characteristic enables GRUs to adapt to abrupt transitions in sequential patterns and therefore works well in dynamic settings, including real-time data streams.
These gates combine to generate a candidate hidden state, which serves as the new information to be fused. The final hidden state is obtained by fusing the candidate state and the previous state, controlled by the update gate.
Comparing GRUs and LSTMs
GRUs and LSTMs differ in complexity and computational requirements, even though they are both designed to handle long-term dependencies.
- Gates: GRUs use two, whereas LSTMs use three (input, forget, and output).
- Memory Handling: GRUs combine the cell and hidden states into a single joint vector, simplifying computations.
- Speed and Efficiency: GRUs are low-memory and low-speed-consuming, and thus can be used in real-time or resource-constrained systems.
- Performance: GRUs are typically as good as LSTMs, at least for tasks that do not require maintaining a very long context.
That is why developers like GRUs in production systems, where speed and efficiency matter more than accuracy.
How GRUs Tackle the Vanishing Gradient Problem?
GRUs are characterized by the important innovation of retaining gradients during backpropagation. Gradients in GRUs do not decay over a sequence of time steps, as was previously the case in traditional RNNs, because they have a direct path of gradient flow through the gating system.
The update gate enables gradients to flow freely without obstruction, so that important information is not lost over many steps. This has the advantage that the model can remember dependencies that were in the sequence much earlier, resolving one of the most long-standing difficulties of sequential modeling.
Besides, GRUs are independent of memory cells and require fewer operations without sacrificing gradient stability. This makes them useful in a job where there is a long, continuous data flow, such as text or Audio.
The Advantages of GRUs
GRUs have numerous convenient features that can be applied to a broad spectrum of machine learning scenarios:
- Computational Efficiency: GRUs have fewer parameters than LSTMs, thus requiring less memory and taking less time to train, which is beneficial for systems that must execute in real time.
- Better Gradient Flow: vanishing gradients are reduced by its gating design, which allows longer-term learning.
- Streamlined Design: This lack of discrete cell states minimizes architectural complexity without affecting performance.
- Good Generalization: GRUs achieve high performance even with smaller datasets, minimizing the risk of overfitting.
- Ease of Integration: They can be easily integrated into more general architectures, such as encoder-decoder or attention-based models, without a major redesign.
GRUs are an effective idea in research and in industry due to these advantages.
Where GRUs Excel: Real-World Applications?
GRUs have shown impressive performance in various sequence-based fields:
- Natural Language Processing: GRUs perform well in text generation, sentiment analysis, and machine translation because they can store contextual information at scale.
- Speech Recognition: They are better at continuous Audio processing because of their time-modeling nature.
- Time-Series Forecasting: GRUs are useful for predicting stock trends and analyzing energy use, and they are great at modeling sequential numerical data.
- Anomaly Detection: GRUs efficiently capture variations in behavioral patterns across domains such as cybersecurity and industrial system monitoring.
- Reinforcement Learning: GRUs are also used to model sequential decision-making in dynamic environments, helping agents remember past actions and rewards.
Their versatility and computational efficiency explain why GRUs remain a preferred choice across both academic and commercial applications.
Conclusion
The Gated Recurrent Unit represents a critical step in the evolution of recurrent neural networks. By intelligently managing memory through update and reset gates, GRUs deliver both the depth of understanding found in LSTMs and the simplicity required for efficient computation. Their ability to overcome vanishing gradients, adapt to various sequence lengths, and integrate seamlessly into modern architectures makes them indispensable for anyone working with time-dependent data.